




This is the first post of a many planned to shed light on the various networking techniques eBPF makes available to a Linux network developer.
I started my career as a network engineer before I found programming interesting.
During this time, I was working with white box networking hardware more often than Linux.
A few years into this role,however, the “commodity hardware” trend took foot, and Linux was being used in the network world far more often.
It has always stood out to me that Linux networking felt different compared to working with traditional network hardware.
In my opinion, this is because Linux is extremely flexible and, from my experience, aims for maximum flexibility with its networking concepts.
This leads to the often feeling that certain networking concepts learned in the traditional network engineering world do not cleanly map to Linux concepts.
For instance, wtf is a veth?
You can describe it as a virtual “wire”, but it is also represented as two network interfaces by Linux.
It’s also an I/O pipe, which is a systems programming thing.
Oh, and it can be plugged into a Linux bridge, in which case one side of the interface disappears.
We’ll be using veths a lot in these posts; figured I’d introduce their flexibility now.
Scenarios like this have driven me to start writing about Linux networking, especially in the context of eBPF.
It doesn’t hurt that it’s also my favorite topic in computer science, so I’m rather motivated to share my knowledge.
I plan on writing a series of posts, each focusing on a particular eBPF networking technique.
Each post should be “bite-sized” and small enough to read and work through in an hour or two.
eBPF is a dense topic and the Linux networking subsystem is (maybe) even more dense, so it’s inevitable that some details necessary for a complete understanding of a technique will be glossed over.
I’ll do my best to link to subsequent reading, kernel source code, or other blog posts to fill in the knowledge gaps where possible.
Without further ado, the first eBPF networking technique I want to cover is packet redirection.
Packet Redirection
Packet redirection is taking a packet from one network interface and injecting it into another.
Let’s illustrate this with a diagram that also depicts our lab topology.
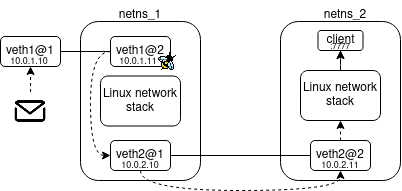
The above illustrates the basic form of an eBPF redirect.
The dotted lines represent the packet’s path while solid lines depict veth pairs.
Our topology consists of two network namespaces bridged together by a veth.
Let’s assume veth1@1 is in the host network namespace providing access to netns_1 and routing is configured for end-to-end connectivity.
A packet is sent to the client in netns_2 listening on 10.0.2.11:7777.
An eBPF program is associated with veth1@2 which will run when a packet is received.
This eBPF program performs an eBPF redirect to veth2@1 which forwards the packet immediately to veth2@2 in netns_2.
From here the Linux network stack will be employed to deliver the packet to the client process (this is called local delivery).
Notice in netns_1 we actually hop over the Linux networking stack when moving the packet towards its final destination.
This is the interesting bit of the technique, we short-circuit packet delivery by jumping over a bunch of kernel functions in the processing of the packet.
In a typical network flow, pretty much like the one we see in netns_2, the Linux network stack would evaluate the packet, passing it to Layer 2 and Layer 3 processing before determining if the packet should be delivered locally or routed out an interface.
If our eBPF program can glean this knowledge, however, we can skip the Linux network stack completely and inject the packet into the egress interface which moves the packet closer to its destination.
A Demonstration
Let’s jump into some code.
I’m going to assume you can build eBPF programs with libbpf, load them, and run them.
If you’re not sure how to do this check out my post here.
You can find the code here
Makefile
MAKEFLAGS += --no-print-directory
IP = sudo ip
NETNS = $(IP) netns
EXEC = $(NETNS) exec
NET_1 = "netns_1"
NET_2 = "netns_2"
up: packet_redirect.bpf.o vmlinux.h
# Purging old environment...
-make down
# Creating network namespaces...
$(NETNS) add $(NET_1)
$(NETNS) add $(NET_2)
# Configuring the following topology...
# |host_ns |netns_1 |netns_2 |
# |veth1@1 10.0.1.10|---|veth1@2 10.0.1.11 "http://who.ldelossa.is/"
# "http://who.ldelossa.is/"veth2@1 10.0.2.10|---|veth2@2 10.0.2.11 |
# "http://who.ldelossa.is/" |server 10.0.2.11:8000 |
$(IP) link add name veth1@1 type veth peer name veth1@2 netns $(NET_1)
$(IP) addr add 10.0.1.10/24 dev veth1@1
$(EXEC) $(NET_1) ip addr add 10.0.1.11/24 dev veth1@2
$(EXEC) $(NET_1) ip link add name veth2@1 type veth peer name veth2@2 netns $(NET_2)
$(EXEC) $(NET_1) ip addr add 10.0.2.10/24 dev veth2@1
$(EXEC) $(NET_2) ip addr add 10.0.2.11/24 dev veth2@2
$(IP) link set veth1@1 up
$(EXEC) $(NET_1) ip link set veth1@2 up
$(EXEC) $(NET_1) ip link set veth2@1 up
$(EXEC) $(NET_2) ip link set veth2@2 up
$(IP) route add 10.0.2.0/24 dev veth1@1
$(EXEC) $(NET_2) ip route add 10.0.1.0/24 dev veth2@2
# veth1@2 in netns_1 must proxy ARP requests for host_ns and netns_2 so
# host_ns can resolve MAC addresses for netns_2 and vice versa.
$(EXEC) $(NET_1) /bin/sh -c 'echo 1 > /proc/sys/net/ipv4/conf/veth1@2/proxy_arp'
# Hardcode veth2@2 to a dummy MAC for sake of demonstration purposes.
$(EXEC) $(NET_2) ip link set dev veth2@2 addr 02:00:00:00:00:00
# Attaching eBPF program...
$(EXEC) $(NET_1) tc qdisc replace dev veth1@2 clsact
$(EXEC) $(NET_1) tc filter replace dev veth1@2 ingress bpf direct-action object-file $< section tc
# LISTENING FOR UDP PACKET @ 10.0.2.11 7777...
# Use 'make listen' to listen for another packet...
@make listen
.PHONY:
down:
$(NETNS) del $(NET_1)
$(NETNS) del $(NET_2)
.PHONY:
listen:
$(EXEC) $(NET_2) nc -u -l 10.0.2.11 7777
packet_redirect.bpf.o:
%.bpf.o: %.bpf.c vmlinux.h
# Compiling eBPF program...
clang -O2 -target bpf -g3 -c $< -o $@
vmlinux.h:
sudo bpftool btf dump file /sys/kernel/btf/vmlinux format c > vmlinux.h
While this may look a little involved, it compiles our eBPF program, sets up our network topology, configures routing, attaches our eBPF program, and starts a listening UDP server for testing all with our default target up.
A large chunk of the up target is creating our two network namespaces, wiring veths together, and adding routes.
I think the general topology setup is self explanatory, however I want to explicitly call out two interesting things happening in this Makefile.
Proxy ARP
# veth1@2 in netns_1 must proxy ARP requests for host_ns and netns_2 so
# host_ns can resolve MAC addresses for netns_2 and vice versa.
$(EXEC) $(NET_1) /bin/sh -c 'echo 1 > /proc/sys/net/ipv4/conf/veth1@2/proxy_arp'
Consider what we’d like to accomplish in our demo.
We want to send a packet to 10.0.2.11 from the host namespace and have it reach the client in netns_2.
When we try to craft a packet toward 10.0.2.11 from the host network namespace we need ARP to resolve a MAC address for this IP so it can be placed in the Layer 2 header.
The interface which owns 10.0.2.11 is only accessible by transiting netns_1 however and netns_1 has no reason to implicitly forward ARP request or responses for interfaces existing on its local links.
So, we need netns_1 to act as a proxy for netns_2, responding on behalf of netns_2 when ARP requests for 10.0.2.11 are encountered.
You could also just hard-code a mapping between 10.0.2.11 and the MAC address of veth1@2 in the host network namespace neighbor table, but I find proxy ARP a bit more elegant as it works without using static mappings.
Attaching eBPF to TC Classifier
$(EXEC) $(NET_1) tc qdisc replace dev veth1@2 clsact
$(EXEC) $(NET_1) tc filter replace dev veth1@2 ingress bpf direct-action object-file $< section tc
The Traffic Control subsystem is used for fine-grain packet queuing, policing, and filtering.
I don’t want to dig too deep into the Traffic Control (TC) subsystem in Linux, as this would be an entire post of its own.
You should read the Traffic Control HOWTO for a better understanding of what those terms mean.
Suffice it to say the TC subsystem can be entered for every packet that it received or transmitted on an interface, making it a great place for eBPF hooks to be applied.
Let’s summarize the above two lines:
- We add a
qdiscof typeclsacttoveth1@2where we expect the eBPF redirect to occur- The
qdiscof typeclsactallows us to attach eBPF filters which are triggered for every packet either entering or leaving the network interface.
- The
- We then add our eBPF filter to the
qdisconveth1@2in theingressdirection instructing our eBPF program to be triggered on every received packet (as opposed toegressdirection for every transmitted packet).- The
direct-actionflag allows our eBPF filter program to actually act like anactionwhich manipulates the packet, instead of aclassifierwhich classifies the packet, allowing our filter to returnTC_ACT_REDIRECTin our demonstration.
- The
This attachment process and the flags used can be a bit confusing without a good mental map of the TC subsystem.
I suggesting reading Traffic Control HOWTO followed by a great post from my colleague: Understanding tc “direct action” mode for BPF.
The former article helps paint a mental picture of the TC subsystem while the latter will help clear the confusion when you notice how the clsact works differently from traditional qdisc implementations.
eBPF Redirect Implementation
redirect.bpf.c
#include "vmlinux.h"
#include The above is our eBPF program which redirects a packet destined to 10.0.2.11.
Let’s walk through this code:
#include "vmlinux.h"
#include We begin by defining some constants we will use later.
Because this is a demonstration we can hard-code some information for simplicity such as the interface ID we plan to redirect our packet to and the destination IP we are snooping for.
SEC("tc")
int redirect(struct __sk_buff *ctx) {
void *data_end = (void *)(__u64)(ctx->data_end);
void *data = (void *)(__u64)(ctx->data);
struct ethhdr *eth;
struct iphdr *ipv4;
int ret;
bpf_printk("redirect: handling packetn");
// bounds check for verifier, packet's data must be at least as large
// as an ethernet header and the non-variable portion of the IPv4 header.
if ((data + sizeof(struct ethhdr) + sizeof(struct iphdr) > data_end))
return TC_ACT_OK;
We are writing a program which runs in the TC subsystem and various loaders (bpftool, tc, libbpf) expect these programs in a ELF section dubbed “tc”, so we put our redirect eBPF program in this section once compiled.
Within the first few lines of redirect we declare the variables we will use in this function.
We set data and data_end to point to the packet’s data and we’ll use these pointers to parse out information in the packet.
Finally, we perform a bounds check on our pointers ensuring the packet’s data buffer carries at least a layer 2 and a layer 3 (not including options) header.
This is required before directly accessing packet data as the Kernel must verify your eBPF program only accesses valid memory.
eth = data;
ipv4 = data + sizeof(struct ethhdr);
bpf_printk("redirect: checking ethernet header for IPv4 proto: %xn", bpf_ntohs(eth->h_proto));
if (bpf_ntohs(eth->h_proto) != ETH_P_IP) return TC_ACT_OK;
bpf_printk("redirect: checking destination address is 10.0.2.11n");
if (bpf_ntohl(ipv4->daddr) != DEST_IP) return TC_ACT_OK;
bpf_printk("redirect: rewriting destination MACn");
eth->h_dest[0] = 0x02;
eth->h_dest[1] = 0x00;
eth->h_dest[2] = 0x00;
eth->h_dest[3] = 0x00;
eth->h_dest[4] = 0x00;
eth->h_dest[5] = 0x00;
bpf_printk("redirect: performing redirectn");
ret = bpf_redirect(TARGET_INTF, 0);
bpf_printk("redirect: result: %dn", ret);
return ret;
After we are sure we can access both the layer 2 and layer 3 headers we can define our pointer variables to them.
Next we do some checks on the headers to ensure this is an IPv4 packet and its destined to 10.0.2.11.
If it is, we need to rewrite the MAC address.
This is necessary because we do a redirect directly from the ingress path on veth1@2 to the ingress path of veth2@1.
Because veth2@1 is a veth it will immediate forward the packet to veth2@2.
If we do not rewrite the MAC ourselves the packet would arrive at veth2@2 with the MAC of veth1@2 and will be dropped during ingress processing due to a MAC mismatch between the packet and the interface.
Remember, we hard-code our MAC address of veth2@2 in our Makefile so we know exactly what to rewrite the MAC to.
# Hardcode veth2@2 to a dummy MAC for sake of demonstration purposes.
$(EXEC) $(NET_2) ip link set dev veth2@2 addr 02:00:00:00:00:00
In a real-world example you’d probably do an eBPF FIB lookup to find the next-hop MAC to rewrite too.
Finally, we call the bpf_redirect helper to perform the eBPF redirect.
We call it with no flag which indicates we are forwarding to the target interface’s ingress path, much more on in [#Ingress and Egress direction](#Ingress and Egress direction)
You can start this demonstration by running make up at the root.
If everything went well you shell will be sitting at this prompt:
# LISTENING FOR UDP PACKET @ 10.0.2.11 7777...
# Use 'make listen' to listen for another packet...
sudo ip netns exec "netns_2" nc -u -l 10.0.2.11 7777
You can then issue this command at the host namespace
echo "hello" | nc -u 10.0.2.11 7777
You should see a ‘hello’ in the terminal where you ran make up.
This indicates the packet successfully redirect to veth2@1 and was delivered to the client in netns_2.
You can edit this code and simply run make up to compile and redeploy it, just make sure you do not have any shells open in either of the namespaces or else the environment cannot be torn down successfully.
How it works (As of Kernel v6.5)
Writing the code and seeing the data arrive on your terminal is oddly satisfying, but lets try to understand how it works under the hood.
First lets look at the signature for bpf_redirect helper itself:
* long bpf_redirect(u32 ifindex, u64 flags)
* Description
* Redirect the packet to another net device of index *ifindex*.
* This helper is somewhat similar to **bpf_clone_redirect**
* (), except that the packet is not cloned, which provides
* increased performance.
*
* Except for XDP, both ingress and egress interfaces can be used
* for redirection. The **BPF_F_INGRESS** value in *flags* is used
* to make the distinction (ingress path is selected if the flag
* is present, egress path otherwise). Currently, XDP only
* supports redirection to the egress interface, and accepts no
* flag at all.
*
* The same effect can also be attained with the more generic
* **bpf_redirect_map** (), which uses a BPF map to store the
* redirect target instead of providing it directly to the helper.
* Return
* For XDP, the helper returns **XDP_REDIRECT** on success or
* **XDP_ABORTED** on error. For other program types, the values
* are **TC_ACT_REDIRECT** on success or **TC_ACT_SHOT** on
* error.
So, pretty simple right, ignoring the bits about XDP (we won’t dig into this yet)?
Give it an interface and a direction and we’ll move the packet there.
But, lets dig into the actual implementation a bit:
BPF_CALL_2(bpf_redirect, u32, ifindex, u64, flags)
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
if (unlikely(flags & (~(BPF_F_INGRESS) | BPF_F_REDIRECT_INTERNAL)))
return TC_ACT_SHOT;
ri->flags = flags;
ri->tgt_index = ifindex;
return TC_ACT_REDIRECT;
}
Now, because I want to keep these articles focused more on demonstrations rather then Kernel code walks, which can get rather lengthily rather quickly, I won’t explain the entire packet flow.
But it may strike you odd, as it struck me, that this implementation is very simple.
All we are doing is setting some flags and returning the TC_ACT_REDIRECT flag to the TC subsystem.
Keep in mind that this eBPF program is running within the context of the TC subsystem.
With a focus on the ingress packet path, let’s take a look at the function responsible for running our eBPF TC filter and handling the response.
implementation
case TC_ACT_REDIRECT:
/* skb_mac_header check was done by cls/act_bpf, so
* we can safely push the L2 header back before
* redirecting to another netdev
*/
__skb_push(skb, skb->mac_len);
if (skb_do_redirect(skb) == -EAGAIN) {
__skb_pull(skb, skb->mac_len);
*another = true;
break;
}
*ret = NET_RX_SUCCESS;
return NULL;
Focusing on what occurs when the eBPF program returns TC_ACT_DIRECT we can see that the *skb_do_redirect* function is invoked.
int skb_do_redirect(struct sk_buff *skb)
{
struct bpf_redirect_info *ri = this_cpu_ptr(&bpf_redirect_info);
struct net *net = dev_net(skb->dev);
struct net_device *dev;
u32 flags = ri->flags;
...
__bpf_redirect(skb, dev, flags);
Taking a look at the interesting bits we see that we retrieve the bpf_redirect_info structure that we stashed our flags into during bpf_redirect and in our case we invoke the __bpf_redirect function.
I’ll leave it to the reader to continue tracing this path our in the code.
It will eventually lead the packet being queued on another network device.
The key take away from the above is that bpf_redirect occurs outside of the eBPF program and the TC subsystem is designed to redirect the packet, not the actual eBPF program.
Ingress and Egress
So I’ve been throwing these terms ‘ingress’ and ’egress’ around pretty loosely and I think there’s some bits worth explaining here.
Within the context of TC, specifically with the clsact qdisc, the terms ‘ingress’ and ’egress’ are referring to where your eBPF program is being attached.
The ingress keyword provided to the tc filter replace command will attach your eBPF program such that it runs for every received packet.
Adversely, egress attaches your eBPF program such that it runs for every transmitted packet.
Within the context of the bpf_redirect helper the terms ingress and egress are really referring to how the Linux subsystem interprets this redirected packet.
The kernel may look at the packet and determine it was just received by an interface and process it via the normal ingress packet flow, passing the packet up to each protocol handler and toward remote (not for us) or local (listening socket exists locally) delivery.
This is what occurs when the default flag of 0 is provided to the bpf_redirect helper.
Another flag exists called BPF_F_EGRESS which instructs the kernel to process this packet as if it was being transmitted.
Instead of the kernel taking the redirected packet and passing it up to protocols, it will pass the packet to the egress packet flow where it will be eventually transmitted by the hardware corresponding to the interface ID passed to the helper.
Let’s use a great tool contributed by my colleagues called Packet Where Are You to demonstrate this.
I keep this handy alias in my shell for quickly debugging eBPF programs.
pwr='docker run --privileged --rm -t --pid=host -v /sys/kernel/debug/:/sys/kernel/debug/ cilium/pwru pwru'
/usr/bin/docker
Now run the following in your shell after pasting that alias in (this can be on your host, the kernel is the kernel, and tracing kernel functions isn’t isolated by any namespacing.)
pwr --output-meta dst 10.0.2.11
Now start the demo environment if you don’t have it running with make up.
If you do have it running and you’ve already sent a packet run make listen to listen for another packet (yes I’m too lazy to script this :-p).
Now, send a packet off and you should see output from pwr.
echo "hello" | nc -u 10.0.2.11 7777
Note: you may actually catch ARP the first time you run this command. If you see logs like arp_solicited, run it one more time after ARP has been processed. You’ll know you have the right output when you see veths being identified with fields like this iface=3(veth1@1) in the log.
Let’s pick out the relevant functions from the output that demonstrate how ingress and egress flags influence the redirect. Lines irrelevant to our explanation are skipped.
0xffff8fc859bc3c00 7 [nc(3184970)] __dev_queue_xmit netns=4026535320 mark=0x0 iface=3(veth1@1) proto=0x0800 mtu=1500 len=48 // veth1@1 preparing to transmit to its veth1@2 pair
0xffff8fc9d885f300 6 [nc(3195225)] __netif_rx netns=4026535460 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=34 // veth1@2 receiving the packet
0xffff8fc9d885f300 6 [<empty>(3195225)] __netif_receive_skb_one_core netns=4026535460 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=34 // veth2@2 begins ingress packet processing
0xffff8fc9d885f300 6 [<empty>(3195225)] tcf_classify netns=4026535460 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=34 // enter TC subsystem where our eBPF program runs
0xffff8fc9d885f300 6 [<empty>(3195225)] skb_do_redirect netns=4026535460 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=48 // invoke a redirection for this packet
0xffff8fc9d885f300 6 [<empty>(3195225)] __bpf_redirect netns=4026535460 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=48 // use our eBPF structure to perform redirect
0xffff8fc9d885f300 6 [<empty>(3195225)] __dev_queue_xmit netns=4026535460 mark=0x0 iface=3 proto=0x0800 mtu=1500 len=48 // the important part!
The above ends with the __dev_queue_xmit function being invoked with iface=3.
In our case this is the veth2@2 interface in netns_1 which is where we redirect the packet to.
The important part here is we immediately wind up in the transmission function for the device, or in other words the packet will be transmitted on veth2@2 after the redirect is processed.
Now, I want us to change packet_redirect.bpf.c:49 to the following:
ret = bpf_redirect(TARGET_INTF, BPF_F_INGRESS);
Run make up to rebuild the environment and follow the same steps to get pwr output.
Let’s pick up right at skb_do_redirect this time.
0xffff8fc8544c3e00 3 [<empty>(3223205)] skb_do_redirect netns=4026535561 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=48
0xffff8fc8544c3e00 3 [<empty>(3223205)] __bpf_redirect netns=4026535561 mark=0x0 iface=2 proto=0x0800 mtu=1500 len=48
0xffff8fc8544c3e00 3 [<empty>(3223205)] netif_rx_internal netns=4026535561 mark=0x0 iface=3 proto=0x0800 mtu=1500 len=34
0xffff8fc8544c3e00 3 [<empty>(3223205)] enqueue_to_backlog netns=4026535561 mark=0x0 iface=3 proto=0x0800 mtu=1500 len=34
0xffff8fc8544c3e00 3 [<empty>(3223205)] __netif_receive_skb netns=4026535561 mark=0x0 iface=3 proto=0x0800 mtu=1500 len=34
0xffff8fc8544c3e00 3 [<empty>(3223205)] __netif_receive_skb_one_core netns=4026535561 mark=0x0 iface=3 proto=0x0800 mtu=1500 len=34
Notice now when the BPF_F_INGRESS flag is used we wind up in the ingress packet path of the kernel with iface=3 which is veth2@2.
The usage of will result in the packet being “recirculated” into netns_1 but with a source interface of veth2@2.
Keep in mind your veth identifications may be slightly different, since I run my demo environment inside a dedicated eBPF development container.
If you run the demo directly on your host machine the output will vary slightly but the general packet flow should remain the same.
Summing it up
eBPF packet redirection is a common technique especially in container orchestration software like Kubernetes.
Cilium, which I work on as my day job, uses this all the time to move packets between containers.
There are a few other ways to perform packet redirection in the Kernel which build on this basic technique.
I’ll be covering those next.
Follow me on the social mediaz if you’re interested in more posts like this.






{kind=link}
Outstanding, kudos